The BeaST is the FreeBSD based reliable storage system concept, it consists of two major families: the BeaST Classic and the BeaST Grid.

The BeaST Classic with RAID arrays and fail-over Arbitrator mechanism + the BeaST Quorum
The BeaST Classic family has dual-controller architecture with RAID Arrays or ZFS storage pools. It turns two commodity servers into a pair of redundant active-active/asymmetric storage controllers which use iSCSI protocol (Fibre Channel in the future) to provide clients with simultaneous access to volumes on the storage system. Both controllers have access to all drives on one or several SATA or SAS drive enclosures. Depending on particular configuration, it allows the BeaST Classic to create wide range of GEOM based software or hardware RAID array types along with ZFS storage pools.

The BeaST Classic with RAID arrays and CTL HA + the BeaST Quorum
The BeaST Classic uses BeaST Quorum (BQ) software in conjunction with CTL High-Availability (CTL HA) or the BeaST Arbitrator (BA) for the fail-over and fail-back operations.
|
The BeaST Classic with RAID Arrays |
The BeaST Classic with zpools |
||
|
BA + BQ |
|||
The BeaST Grid family utilise computer nodes instead of drive enclosures.
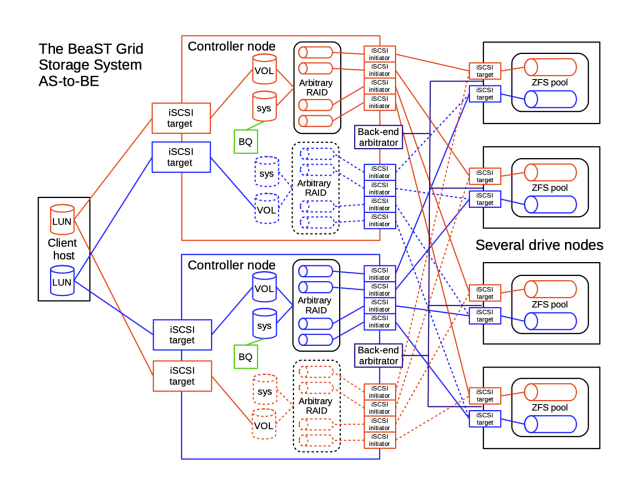
The BeaST Grid with RAID arrays and CTL HA + the BeaST Quorum
| The BeaST Grid with RAID arrays |
The BeaST Grid with zpools |
||
|
BA + BQ |
CTL HA + BQ |
BA + BQ |
|
Color depicts the current development state of the branches. For example, you can achieve success testing the BeaST Classic with RAID arrays and the BeaST Arbitator + BeaST Quorum, but you will have troubles with ZFS implementations.
Current documentation
 The BeaST Grid with RAID arrays and CTL HA
The BeaST Grid with RAID arrays and CTL HA
Configuring Linux server to work with the BeaST storage system over iSCSI protocol Version 1.1, 2018.10.26
The BeaST Classic – dual-controller storage system with ZFS and CTL HA
The BeaST Classic – dual-controller storage system with RAID arrays and CTL HA Version 1.1, 2018.06.03
Approaching online zpool switching between two FreeBSD machines
The BeaST Classic – dual-controller storage system with RAID arrays and fail-over Arbitrator mechanism
Simple quorum drive for the FreeBSD CTL HA and the BeaST storage system
The BeaST Quorum device source code 
First look at the renewed CTL High Availability implementation in FreeBSD Version 1.1, 2016.10.20
Using SSD as the level two cache for the FreeBSD dual-controller storage array 2016.07.21
Archive documentation
Warning! The BeaST storage system is the study of the storage systems technology. All the ideas, algorithms and solutions are at concept, development and testing stages. Do not implement the BeaST in production as there is no guarantee that you will not lose data.


I am really enjoying reading your articles in BSD Magazine on this subject, thank you for writing the articles and sharing them with the BSD community!
I have been trying to recreate your setup from the first article, “FreeBSD based dual-controller storage system concept”. I have been running into issues and I was wondering if you had seen the below error message? When “clnt-1” connects to “ctrl-a” with the iscsictl command, the dmesg output for da0 matches your output. However, for da1, instead of getting a line stating “da1: 98MB (…..)” like in your article, I get “Attempt to query device size failed: NOT READY, Logical unit not ready, manual”. The entire output for da1 is listed below.
“da1 at scsii1 bus 0 scbus9 target 0 lun 1”
“da1: Fixed Direct Access SPC-4 SCSI device”
“da1: Serial Number MYSERIAL 2”
“da1: 150.000MB/s transfers”
“da1: Command Queueing enabled”
“da1: Attempt to query device size failed: NOT READY, Logical unit not ready, manual”.
The same thing happens when I add the “ctrl-B” session with da3. The output for da2 matches your article exactly, but for da3 I am getting the “Attempt to query device size failed: NOT READY, Logical unit not ready, manual” message. On both controllers, the mirrors appear to be healthy and happy. The gmirror command is not showing any oddities on the controller. The iSCSI sessions on the private and public connections are all connected as well.
Did you ever encounter this error? If so, do you have any clues or tips you may be able to share?
LikeLiked by 1 person
Hi SpaceGhostEngineer,
in such situations “not ready” messages usually mean that LUN is defined in /etc/ctl.conf but it is actually can’t be reached. So check if the block device is accessible then execute “service ctld reload” to force ctld to re-read the configuration file or even “service ctld restart” to restart the daemon. Hope this advice can help you. Actually, I’m now finishing automatic failover/failback functions of the basic BeaST architecture (without ZFS), so I hope to update previous or write new papers on it.
LikeLike